LLMs Get Lost In Multi-Turn Conversation
Abstract
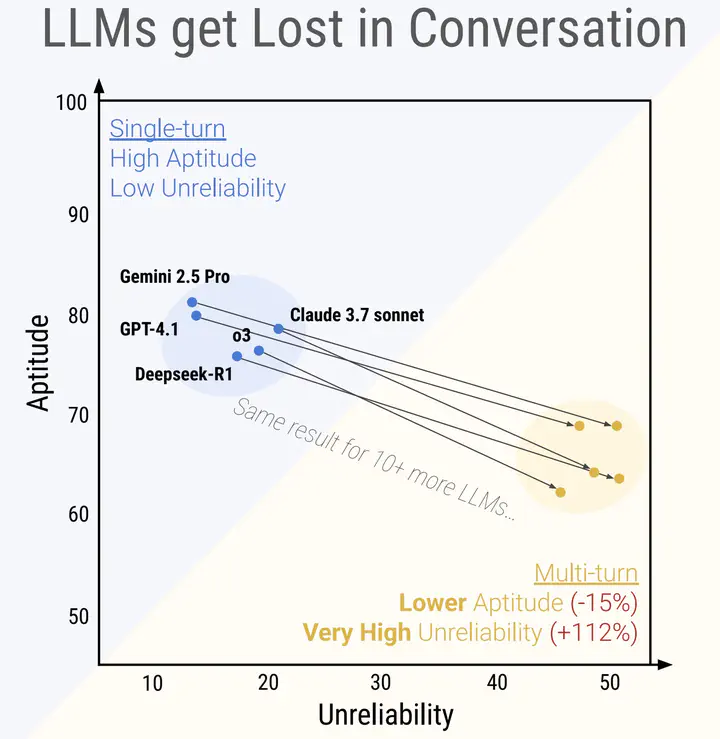
In this talk, I will present a systematic evaluation of large language models (LLMs) in multi-turn conversational settings, focusing on the “lost-in-conversation” phenomenon. I will introduce a novel benchmarking methodology that transforms single-turn tasks into multi-turn interactions using a simulated user and classifier-based evaluation pipeline. Through large-scale simulations across diverse tasks, I will demonstrate that LLMs often fail to recover from early misinterpretations, exhibit high unreliability, and produce verbose or bloated responses. I will also discuss the limitations of current mitigation strategies such as agent-based concatenation and temperature tuning, and highlight the implications for future LLM design and evaluation.
Duc Q. Nguyen
CS PhD Student
My research interests include Generative Models, Graph Representation Learning, and Probabilistic Machine Learning. My application interests include Natural Language Processing, Healthcare, and Education.